外观
对话模型部署教程
本文以ChatGLM3-6B开源模型为例,介绍如何将对话模型部署至容器实例中
首先,请阅读各模型的官方文档,根据模型所支持的框架,python版本等信息寻找匹配的镜像源创建实例。
容器创建完成后,进入终端界面,从模型的官方Github上克隆模型仓库。
git clone https://github.com/THUDM/ChatGLM3
进入文件夹: cd ChatGLM3
使用pip安装模型依赖项:
pip install -r requirements.txt
下载模型至实例中,首先需要安装GIT-LFS
curl -s https://packagecloud.io/install/repositories/github/git-lfs/script.deb.sh | sudo bash
sudo apt-get install git-lfs
下载模型
git clone https://huggingface.co/THUDM/chatglm3-6b
至此,模型已在容器中部署完成。
代码调用
python
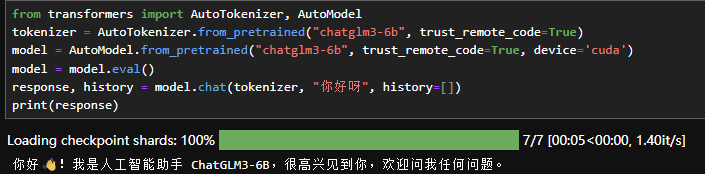
from transformers import AutoTokenizer, AutoModel
tokenizer = AutoTokenizer.from_pretrained("THUDM/chatglm3-6b", trust_remote_code=True)
model = AutoModel.from_pretrained("THUDM/chatglm3-6b", trust_remote_code=True, device='cuda')
model = model.eval()
response, history = model.chat(tokenizer, "你好呀", history=[])
print(response)其中,''THUDM/chatglm3-6b"为用户模型所在目录,请根据你下载模型的位置自行更改。
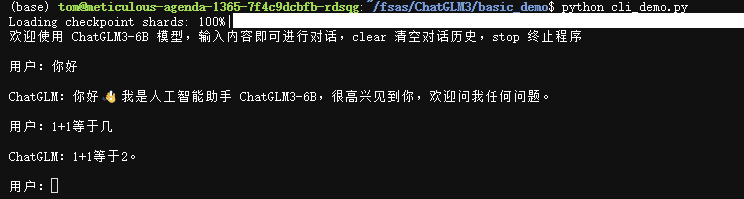
命令行对话
将终端切至basic_demo目录下,点击cli_demo.py文件,将模型目录修改为你模型所在的位置。修改完后,运行如下代码:
python cli_demo.py
在用户栏输入对话,模型即会推理后回答你。回答速度取决于容器实例的GPU性能
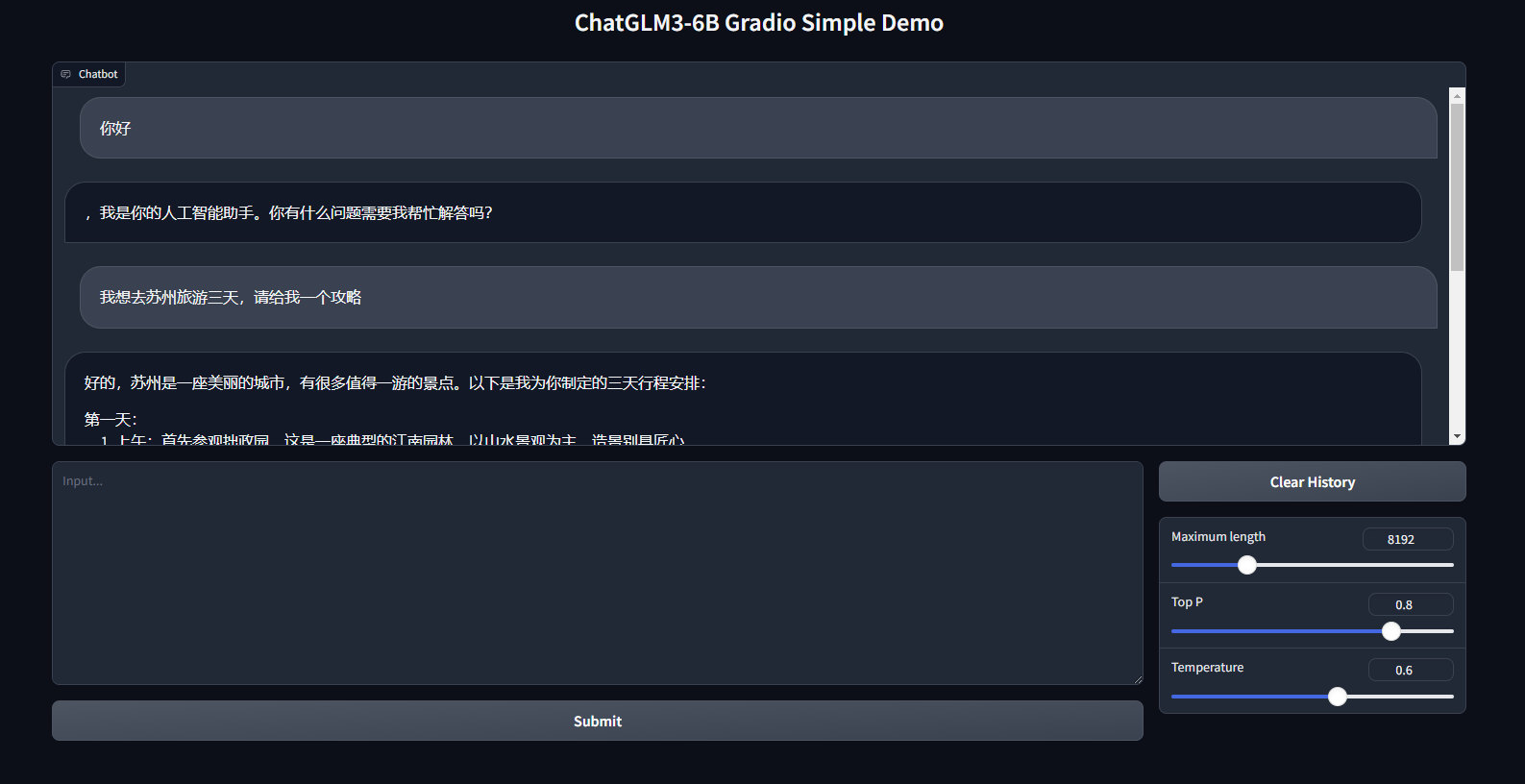
WebUI界面对话
有基于Gradio和Streamlit的界面
首先,安装Gradio和Streamlit
pip install gradio
pip install streamlit
为了能在应用服务里启动,我们需要采取一些步骤
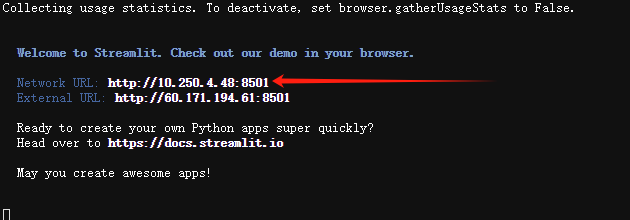
首先,在终端输入streamlit hello,将其生成的第一个IP地址记录下来。如图所示,为10.250.4.48
打开web_demo_gradio.py,进行如图修改。
将红色箭头处内容修改为容器中模型所在目录

将server_name修改为上述IP地址,server_port修改为创建实例时所设置的端口号。
回到终端界面,运行如下命令:
python web_demo_gradio.py
启动后,通过实例的应用服务功能进入网页demo
